

Not only was the creation of the internet the largest technological breakthrough of the 20th century, it also happened to become a hidden double-edged sword. The internet has allowed us to access information and communicate at unprecedented levels, across the globe. Yet, this comes at an enormous cost. The human cost. Hidden behind computer screens, we enjoy a security blanket of anonymity, which emboldens some to say and do things that are labeled as disturbing in a public setting. Throughout the lifespan of the internet, these people - dubbed “trolls” - have evolved from provocative users in online chatrooms to bullies. Now, trolls infest every layer of the internet and show themselves in online activities from videogames to YouTube comment sections.
This trend of online harrassment has become so prevalant that it has been classified as “cyberbullying” and is a known cause for depression, self-harm, and suicides. As documented by Stop Bullying, most instances of cyberbullying takes place through text messaging, online messaging, direct messaging, and online chatting.
Let’s try to end it.
Ideally, a toxicity detection platform will be able to identify hate/toxic language and classify it into categories based on what was written. Once classified, the speech will be given a rating from 0 - 1 (0 being not toxic and 1 being extremely toxic). From there, users of the model can implement systems to mitigate the toxic language.
Have you ever wondered how a Neural Network works?
Let’s examine the human mind first. Our brain is made up of 86 billion neurons. Each neuron is responsible for the transport and uptake of neurotransmitters - chemicals that pass information between brain cells. Modeled loosely on the human brain, a neural net consists of thousands or even millions of simple processing nodes that are densely interconnected.
The human brain consists of 3 parts: cerebrum, cerebellum, and brainstem. Of which, Neural Networks are modeled off of the 4 lobes of the cerebrum.
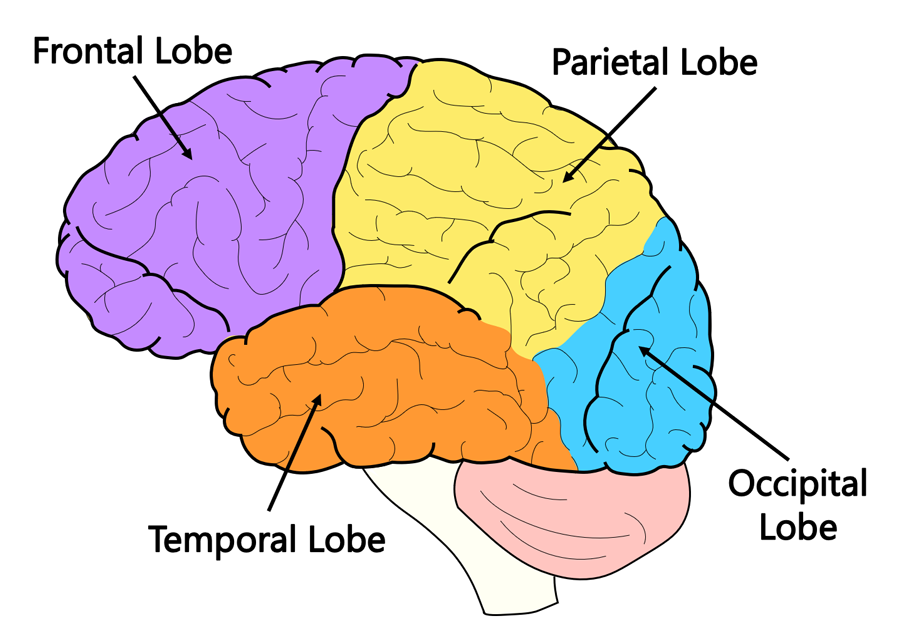
The temporal lobe is the part of the brain that is associated with long-term memory. Separately, the artificial neural network was the first type of neural network that had this long-term memory property. In this sense, many researchers have compared artificial neural networks with the temporal lobe of the human brain.
Similarly, the occipital lobe is the component of the brain that powers our vision. Since convolutional neural networks are typically used to solve computer vision problems, you could say that they are equivalent to the occipital lobe in the brain.
As mentioned, recurrent neural networks are used to solve time series problems. They can learn from events that have happened in recent previous iterations of their training stage. In this way, they are often compared to the frontal lobe of the brain – which powers our short-term memory.
Moreover, the structure of convolutional neural networks is most similar to that of the Frontal Lobe. The layers of neurons are arranged in such a way as to cover the entire visual field avoiding the piecemeal image processing problem of traditional neural networks.
In short, the most common neural networks are based off of the lobes in our brains!
Before we dive into what the best choice is for our Toxicity Detection model, we have to understand what each Neural Network is.
RNN is an artificial neural network where connections between nodes forms a directed graph along a sequence. Basically, neural networks blocks and cells (nodes) are linked together like a chain. Each block passes a message on to a successor (and/or predecessor if you implement a bidirectional LSTM). This architecture allows an RNN model to retain previous information and act like short-term memory. This is very beneficial for textual data as text is sequential.
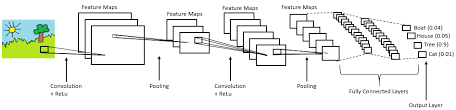
CNN is a deep, feed-forward artificial neural network where the connection between nodes does not form a cycle. CNN’s are organized by stacks of distinct layers that transform the input volume into a distinct output volume through differentiable functions. There are several different types of layers that can be used. Convolutional Neural Networks are extremely useful for identifying and classifying spacial data. This means its primarily meant for image classification, yet shows promise in the NLP field. Patterns can be identified regardless of their position in a sentence. For example, a CNN could classify words like “I hate” or “extremely cool” regardless of their position in a sentence.
Based on the specifications and inputs of our Toxicity Detection Model, we should use a Recurrent Neural Network.
Why RNN?
“Hate is a strong word. You’re vocabulary is okay.”
Based on the sequential learning algorithm that is implemented in its architecture, an RNN model will easily be able to classify that this is a neutral statement. However, a CNN - which is more tuned for pattern detection - will pick up the words “Hate” and “you”, and skew the grade of the statement to moderate/extreme toxicity. This can be rectified with word vectors, but its simply simpler (pun intended) to go with a model that meets our needs exactly. A nice acronym to remember is KISS. Keep It Simple Stupid!
Now that we have decided our model, let’s get to work!
Word Embeddings
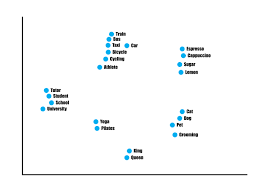
Though you and I are able to understand words, our machine-learning algorithm does not. That’s why we must display the words as a separate vector. Computers are very capable of making mathematical calculations and discovering patterns through that. Basically, we are converting our english language into a language that the algorithm can understand. This is done through mathematical representations of words, known as “word embeddings”.
Word embeddings are in fact a class of techniques where individual words are represented as real-valued vectors in a predefined vector space. Each word is mapped to a vector and the vector values are learned in a way that resembles a neural network, and hence the technique is often lumped into the field of deep learning.
The key to the approach is the idea of using a distributed representation for each word.
The distributed representation is learned based on the usage of words. This allows words that are used in similar ways to result in having similar representations, naturally capturing their meaning.
By utilizing GloVe word embeddings provided by the Natural Language Processing Group at Stanford, we can benefit the Toxicity Detection Model since word embeddings are learned representations of words that are displayed as mathematical vectors. As the toxicity detection model will only be dealing with text/natural language, having GloVe word embeddings simplifies and improves the accuracy of toxicity detection.
GloVe (Global Vectors for Word Representation) is an alternate method to create word embeddings. It is based on matrix factorization techniques on the word-context matrix. A large matrix of co-occurrence information is constructed and you count each “word” (the rows), and how frequently we see this word in some “context” (the columns) in a large corpus. Usually, we scan our corpus in the following manner: for each term, we look for context terms within some area defined by a window-size before the term and a window-size after the term. Also, we give less weight for more distant words. - https://www.mygreatlearning.com/blog/word-embedding/
Getting the Data
Without oil, an engine can’t function. This is the same for our RNN model. Data is today’s oil. It fuels our machine-learning algorithms. ML is only as good as the data we feed it!

Finding good datasets is half the work of building a successful ML model. Some good resources to find models are:
You can find many datasets to fit your specific needs, but for this blog we will be using this dataset found on Kaggle.
Much like oil, datasets must be processed and filtered in order to give the best accuracy and results. After all, you wouldn’t want your car processing diesel if its a gasoline only car. (Unless you’re the Mythbusters)
Partial data taken from test.csv:
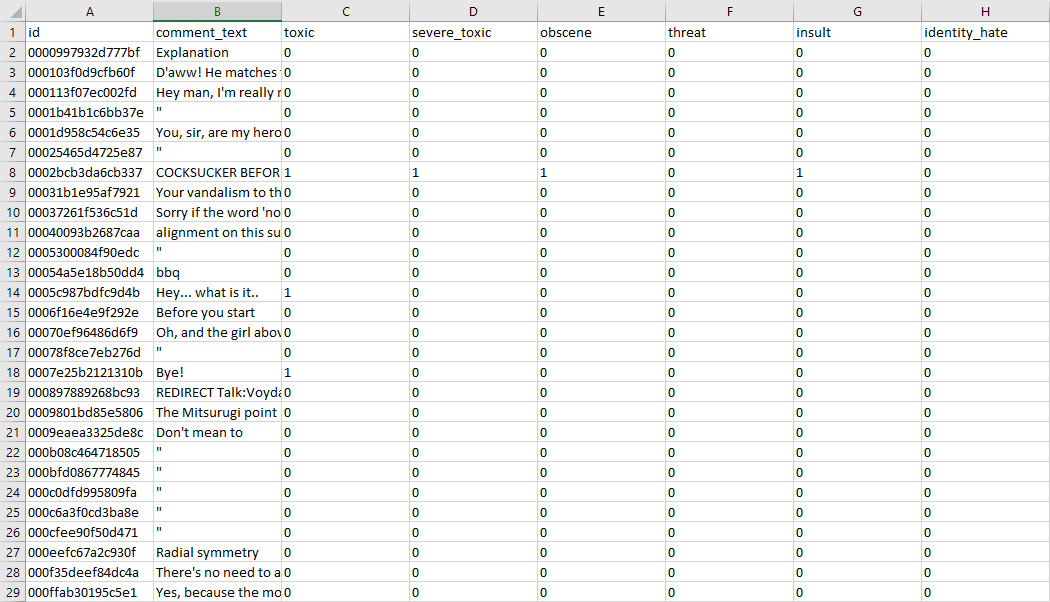
Hmmm… very messy indeed. Within the first 29 lines, I can notice several spelling mistakes, contractions, and case issues. In order for our data to be successfully analyzed, we must have it match the Stanford word embeds as much as possible.
Rules that must be implemented:
Converting to lowercase
Converting all your data to lowercase helps in preprocessing and later stages of Natural Language Processing. It removes unecessary white-noise and will make your model more accurate. Capitalized words typically are at the start of each sentence, which as we know, will have a different meaning/implementation when compared to the same word in the middle of the sentence. Your model may treat a word which is in the beginning of a sentence with a capital letter different from the same word which appears later in the sentence but without any capital letter. This will throw off your accuracy.
def convert_to_lower_case(text):
"""
Splits text by space and loops through list of text and converts to lowercase
"""
return " ".join(text.lower() for text in text.split())
Input: The FitnessGram™ Pacer Test is a multistage aerobic capacity test that progressively gets more difficult as it continues.
Output: the fitnessgram pacer test is a multistage aerobic capacity test that progressively gets more difficult as it continues.
Contraction Mapping
By implementing Contraction Mapping into the filtering process, we are making the data more presentable for our ML model. In today’s fast-paced world, we communicate through text messages, emails, and social media. With so much to say, we rely on abbreviations and shortened forms of words to text people. Therefore, it is imperative that we turn the abbreviations and short form words into an analyzable form.
import contractions
def contraction_mapping(text):
# Handle the special characters that different platforms use as an apostrophe
specials = ["’", "‘", "´", "`"]
for s in specials:
text = text.replace(s, "'")
# Split the text by space, and return the "fixed" contraction through the
# contractions package
text = ' '.join(contractions.fix(text) for text in text.split(" ")])
return text
Input: He'd be amazed by ur ingenuity!
Output: He would be amazed by your ingenuity! (Note: paired with spell check to resolve "ur" to "your")
Correct Spelling
Unfortunately, spelling mistakes are a common, yet detrimental factor to consider for NLP. this is because GLoVe word embeddings (mentioned above), use accurate spelling to represent the connections between words. When words are misspelled, they become out-of-vocabulary (OOV) words - words that were unseen during training time. By correcting misspelled words, we greatly increase the accuracy of the model.
from spellchecker import SpellChecker
spell = SpellChecker()
def fix_spelling_mistakes(text):
orig_words = text.split()
return " ".join(spell.correction(word) for word in orig_words)
You can use TextBlob.correct() to achieve a similar result. However, I discovered that TextBlob frequently made mistakes when given recent terms. For example, it would mistakenly correct “covid-19” to “could 19”, and “ebola” to “ebook”. Given such a large discrepancy, I opted with a more accurate package.
Input: i am bahd at speling werds
Output: i am bad at spelling words
Remove Punctuation
By removing punctuation, we are helping our NLP model get rid of the unhelpful bits of data - known as “noise”.
def remove_punctuations(text):
return text.replace(r'[^\w\s]', '')
By utilizing regex (Regular Expression), we can effectively remove all instances of punctuation without having to implmement much code.
Input: Hello! My name is Jeff!
Output: Hello My name is Jeff
Removing Emojis
Emojis are a common occurence in everyday text - especially on social media platforms. Unfortunately, they do not contribute much to toxicity detection as the emojis themselves cannot be intepreted/graded using the same method we are using for text. As a result, it functions as unwanted noise and must be removed.
def remove_emojis(text):
regrex_pattern = re.compile(pattern = "["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
"]+", flags = re.UNICODE)
return regrex_pattern.sub(r'',text)
Remove Stop Words
“What are stop words?”, you might ask. Stop words are a set of commonly used words that bring no value to language processing. “a”, “an”, “the” are some examples of stop words. Since they are so prevalant in the English language, their usages can dilute the accuracy of NLP models and is unwanted noise during training. It is common practice to remove stop words during filtering.
from stop_words import get_stop_words
from nltk.corpus import stopwords
def remove_stop_words()
stop_words = list(get_stop_words('en')) #About 900 stopwords
nltk_words = list(stopwords.words('english')) #About 150 stopwords
stop_words.extend(nltk_words)
return " ".join(x for x in text.split() if x not in stop_words)
This code example combines the stopword lists from nltk and the stop_words library to create a more comprehensive filtered words list.
Input: The english language is exceptionally confusing.
Output: english language exceptionally confusing.
Apply Lemmatization
Lemmatization is process of grouping inflected forms of a specific word together so it can be analyzed as a single item. This is achieved by transforming inflected forms of a word into its base form (lemma aka dictionary form).
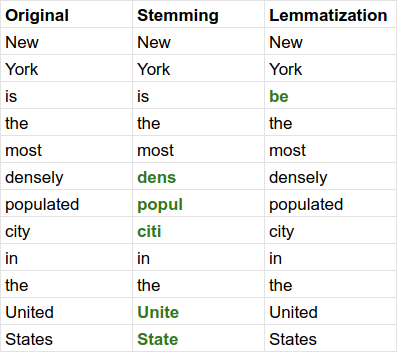
In the above image, you can see a comparison between lemmatization and stemming - which is the process of removing letters until a word is reduced to its suffixes and prefixes. It can also be reduced to the roots of a known lemma.
import spacy
nlp = spacy.load('en_core_web_sm', disable=['parser', 'ner'])
def lemmatise(text):
document = nlp(text)
return " ".join([token.lemma_ for token in document])
Lemmatization can easily be implemented through the spacy library.
Input: lemmatisation can be used for many purposes
Output: lemmatization can be use for many purpose
Now that we’ve implemented data processing and filtering, lets look at RNN Models.
Recurrent Neural Network
Before we dive straight into RNN’s and how to create them, we should discuss the basics. Recurrent Neural Networks process sequences of information - stocks, gas prices, text messages - each individual element at a time while retaining memory of the previous elements.
This memory allows the neural network to learn “long-term dependencies” in succession. In other words, RNN’s can take the entire context of an input into consideration when prediction making. This is especially beneficial towards our Toxicity Detection as the context of sentences is what we are trying to analyze. RNN’s mimic the human way of processing sequences: instead of analyzing individual characters of a sentence, it considers the entire sentence. Take this sentence for example:
“The introduction to the blog was confusing and boring, but as it progressed, I became engrossed in the material.”
A typical machine-learning algorithm would most likely view this sentence as a negative interpretation of the blog. However, an RNN model would consider the contrast between the beginning of the sentence and the end of the sentence, through the use of a coordinating conjunction - represented by “but as it progressed”.
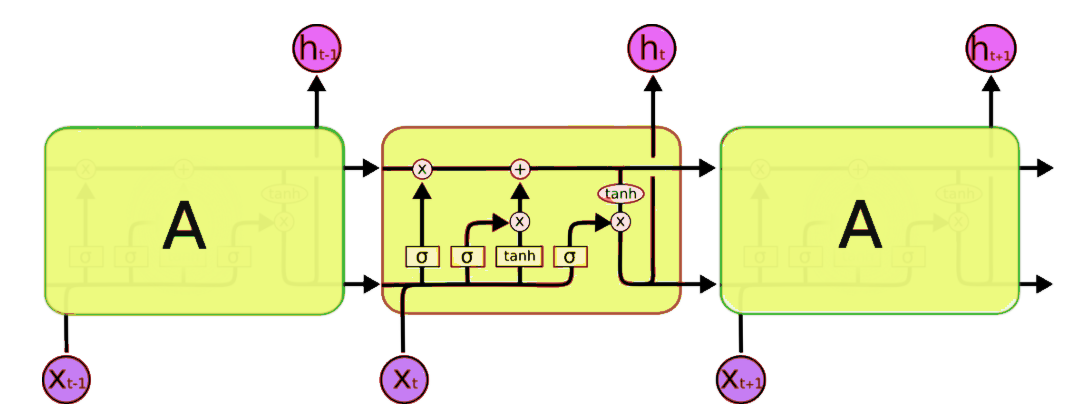
Although the memory functionality is cool and all, let’s discuss how it’s implemented in a Recurrent Neural Network. At the core of each RNN Model lies a layer made up of memory cells. The most popular one being Long Short-Term Memory (or LSTM for short). The LSTM cell is responsible for maintaining cell state as well as ensuring that the signal - information stored in the form of a gradient - is not lost during the sequence. An LSTM considers the current word, carry, and cell state at each step of the way.
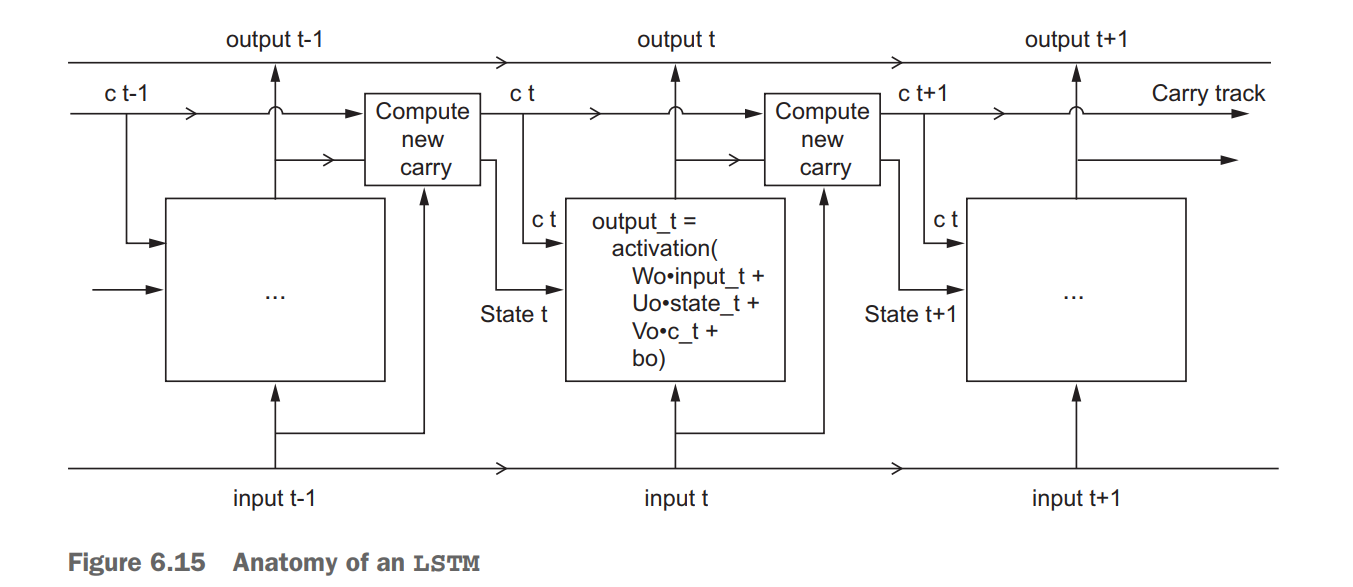
RNN Structure
There are many ways of training our RNN Model to detect the toxicity of
Thank you for reading this blog! Unfortunately, it is incomplete :(. Check in tomorrow!